Learning Temporal Regularity in Video Sequences
Mahmudul Hasan, Jonghyun Choi, Jan Neumann, Amit K. Roy-Chowdhury, and Larry Davis
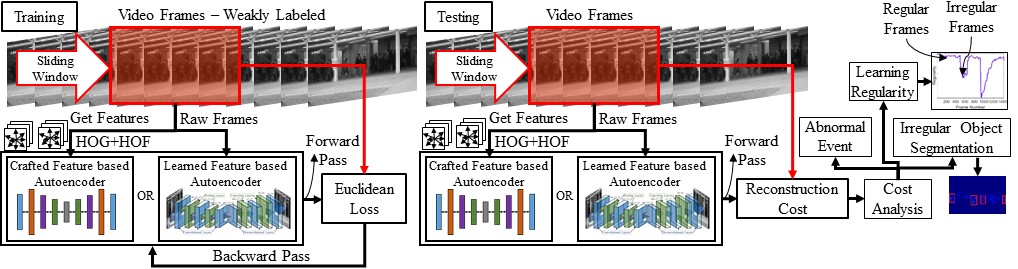
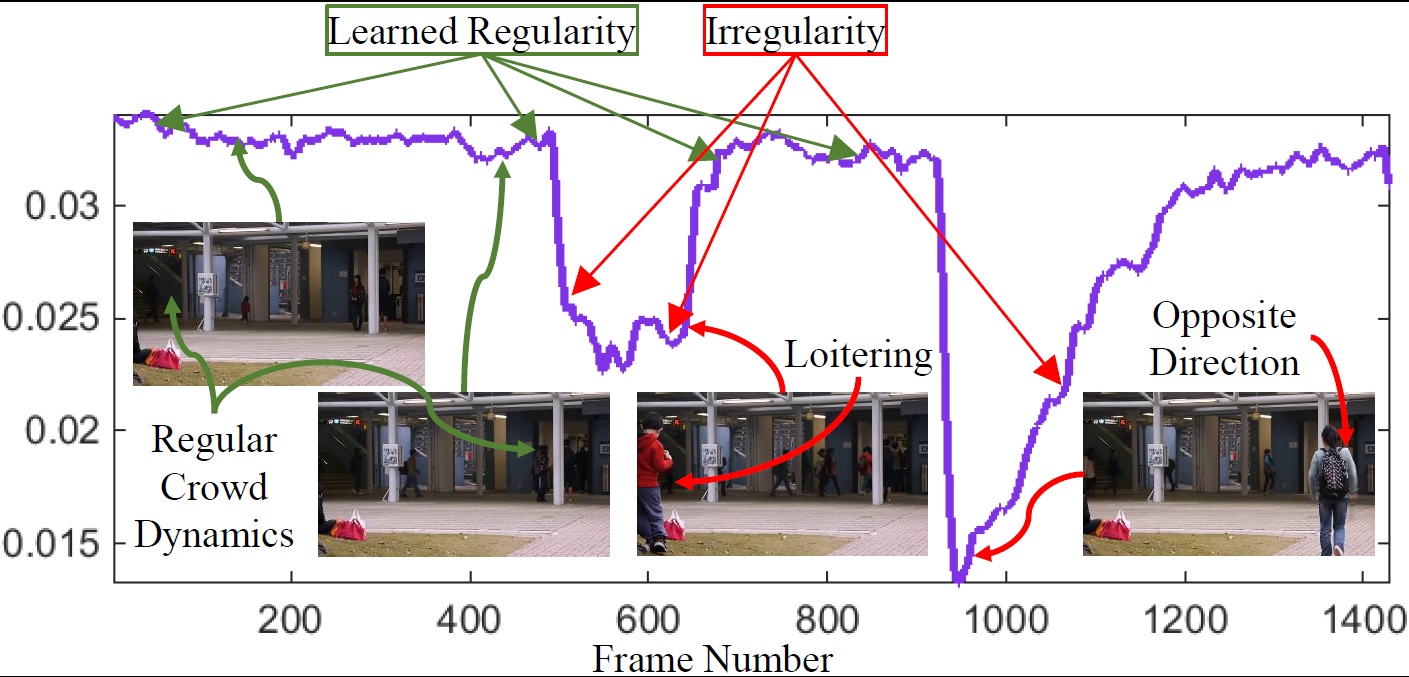
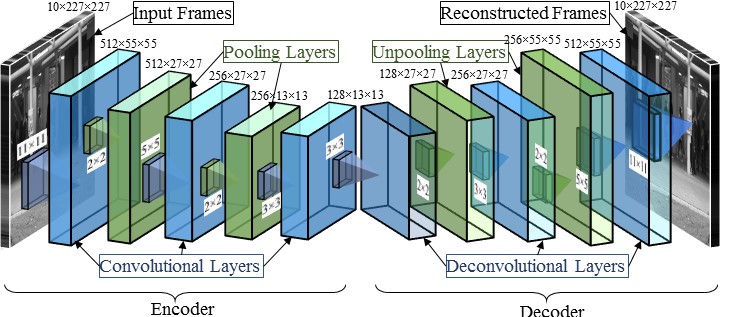
Perceiving meaningful activities in a long video sequence is a challenging problem due to ambiguous definition of `meaningfulness' as well as noise and clutter in the scene. To address the problem under such difficulties, we approach it as a problem of learning regular patterns using multiple sources with very limited supervision. % requiring training videos of regular scenes. Specifically, we propose an approach that builds upon an autoencoder because of its ability to work with little to no supervision. We first leverage upon the conventional spatio-temporal local features and learn an autoencoder. Then, we build a fully convolutional autoencoder to learn both the local features and the classifiers in a single framework. We evaluate our method in both qualitative and quantitative ways; showing the learned regularity of videos in various aspects and demonstrating competitive performance on anomaly detection datasets as an application.